4. LLM Architecture (Part 02)
GPT model
-
Ở phần đầu ta đã triển khai kiến trúc tổng quan của GPT qua
DummyGPTModel, nhưng các thành phần như DummyTransformerBlock & DummyLayerNorm vẫn chưa được khởi tạo. -
Trong phần này ta sẽ thay thế chúng bằng các lớp
TransformerBlock&LayerNormthực tế để cho ra một phiên bản hoàn chỉnh, hoạt động được của mô hình GPT-2 nguyên bản với 124M tham số. Cùng nhìn lại cấu trúc tổng thể của GPT-2 qua hình sau đây: -
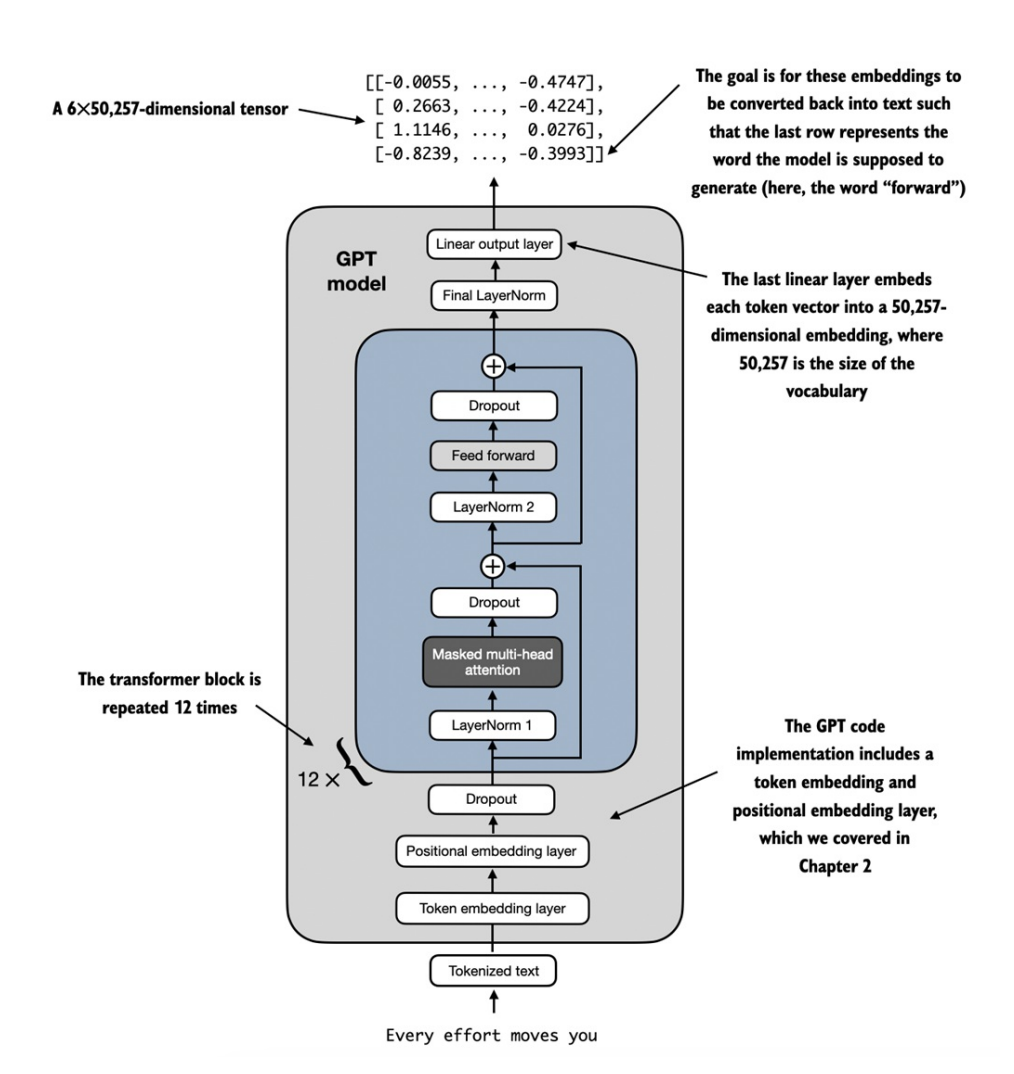
-
Với _GPT-2 124M tham số, Transformer Block được lặp lại 12 lần (điều chỉnh qua n_layers). Tương tự với GPT-2 1542M tham số là 36 lần. Đầu ra của Transformer Block cuối cùng sẽ đi qua 1 bước chuẩn hóa LayerNorm trước khi đi tới output layer. Lớp này ánh xạ đầu ra của Transformer vào 1 không gian cao chiều (trong trường hợp này là 50.257 chiều - vocab_size).
Tại sao output không phải là 1 số mà lại là 1 vector?
-
Vector đầu ra cuối cùng của Transformer (thường có kích thước 768 hoặc 1024) khi đi qua lớp Linear cuối cùng sẽ được ánh xạ tuyến tính lên kích thước tương đương với bộ từ vựng (vocabulary size).
-
Nếu bộ từ vựng có 50.257 từ, vector đầu ra sẽ được chuyển thành 1 vector có độ dài 50.257, được gọi là các
logits. Mỗi con số trong vector đại diện cho một "điểm số" của một từ tương ứng trong từ điển. -
Các logits này sẽ được chuyển đổi sang phân phối xác suất, với mỗi vị trí trong vector sẽ là 1 con số thuộc khoảng [0, 1], và tổng của chúng bằng 1. Hệ thống sẽ chọn ra những index của phần tử có xác suất cao nhất (hoặc chọn ngẫu nhiên dựa trên xác suất), bộ Tokenizer sẽ mapping từ index sang văn bản.
-
-
Code được triển khai tại phần
7. GPT Modeltrong11. Placeholder-GPT.ipynb.
Generate text
-
Quá trình mà một mô hình GPT chuyển đổi từ các tensor đầu ra thành văn bản bao gồm nhiều bước, như được minh họa trong hình dưới đây:
-
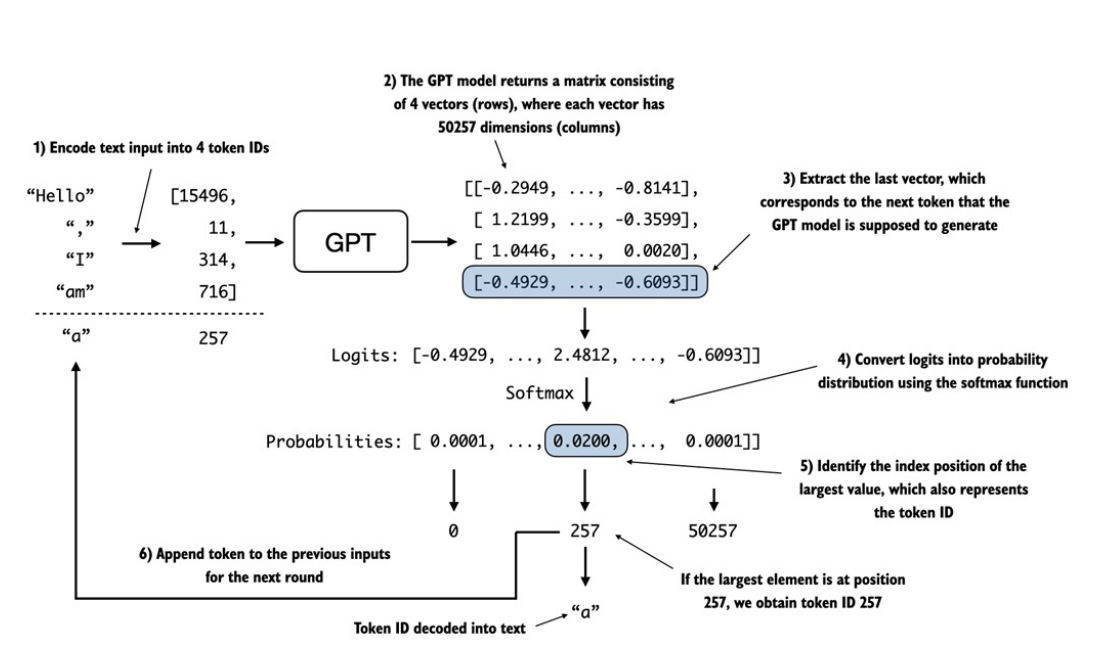
-
Khi đưa 4 tokens vào mô hình GPT, lớp đầu ra sẽ trả về
4 vector logits(1 vector cho mỗi vị trí). Từ vector cuối cùng ta tính xác suất để cho ra được vị trí nào có xác suất lớn nhất, từ đó ánh xạ từ ID sang token tiếp theo (token thứ 5). Cứ lặp lại các bước như vậy đến khi đạt được số lượng token được tạo ra do người dùng chỉ định. -
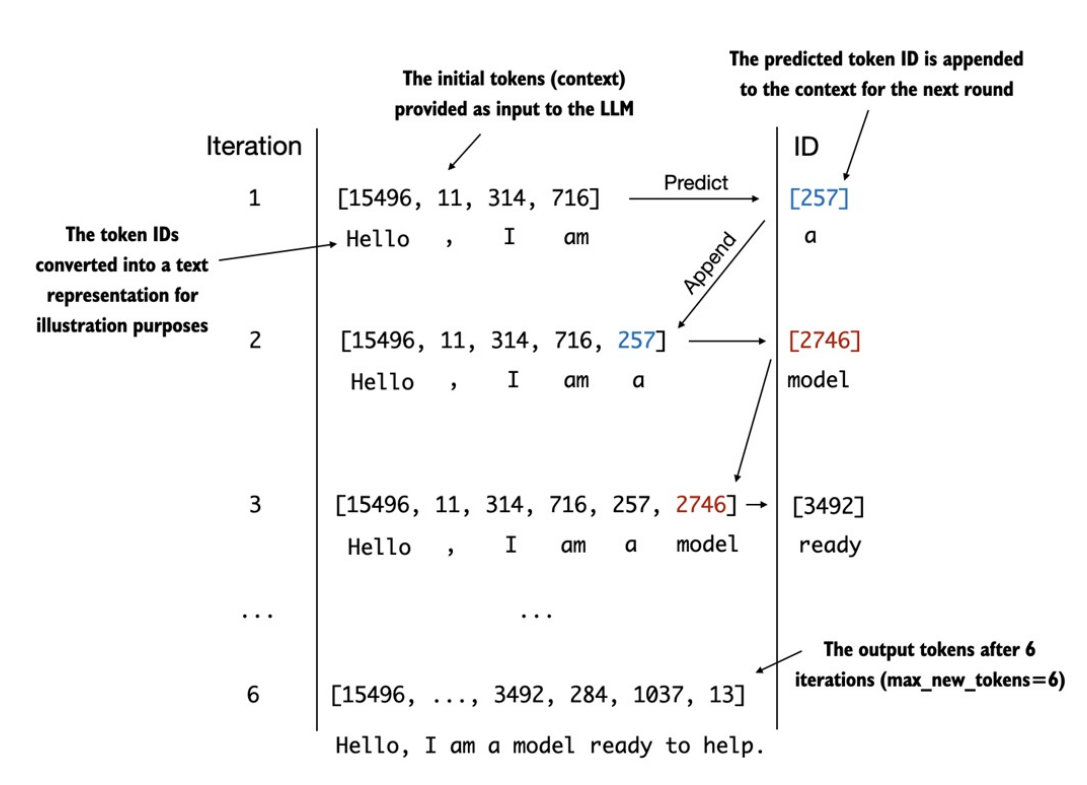
-
Hàm
generate_text_simple()xem thêm tại phần8. Generate texttrong11. Placeholder-GPT.ipynb.
- Như vậy là chúng ta đã hoàn thành việc sinh văn bản từ 1 GPT model khởi tạo ban đầu. Ở chương sau ta sẽ tiến hành huấn luyện để mô hình có thể sinh văn bản có nghĩa.