3. Coding Attention Mechanisms (Part 05)
3.6. Cải tiến từ single-head attention sang multi-head attention
-
Ở phần này ta sẽ mở rộng
multi-head attentiontừcausal attention. -
Triển khai đầu tiên sẽ xây dựng module multi-head attention bằng cách xếp chồng nhiều module
CausalAttentionđể dễ hình dung. -
Sau đó triển khai tiếp theo sẽ xây dựng cùng 1 module multi-head attention đó theo một cách phức tạp hơn để mang lại hiệu suất tính toán cao hơn.
Xếp chồng nhiều lớp single-head attention
-
Khi triển khai multi-head attention, ta cần tạo ra nhiều
instancescủa self-attention. Mỗi instance này sẽ có bộ weights riêng biệt, sau đó kết quả đầu ra sẽ được kết hợp với nhau. Việc sử dụng nhiều instances có thể tốn tài nguyên tính toán, nhưng là yếu tố then chốt cho khả năng nhận diện các đặc trưng phức tạp - đặc điểm nổi bật của LLM dựa trên Transformer. -
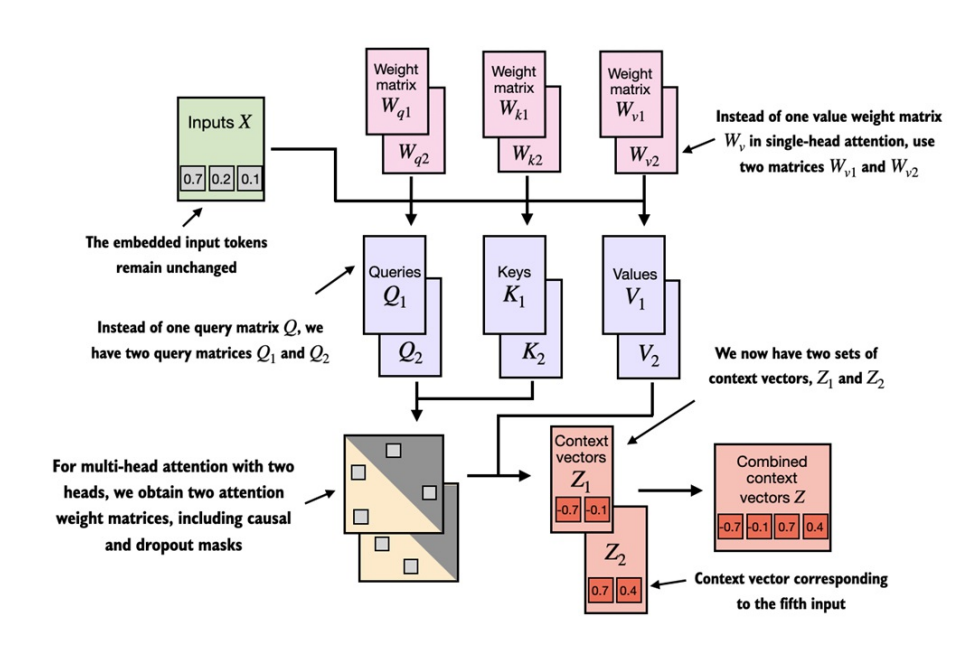
-
Module multi-head attention trên mô tả 2 module single-head attention xếp chồng lên nhau. Thay vì sử dụng 1 ma trận duy nhất để tính ma trận vector values, giờ ta có 2 ma trận weights & , tương tự với & . Kết quả ta thu được 2 bộ context vector & , sau đó kết hợp thành 1 bộ duy nhất.
-
Code triển khai xem tại
10. Multi-head-attention.ipynb. -
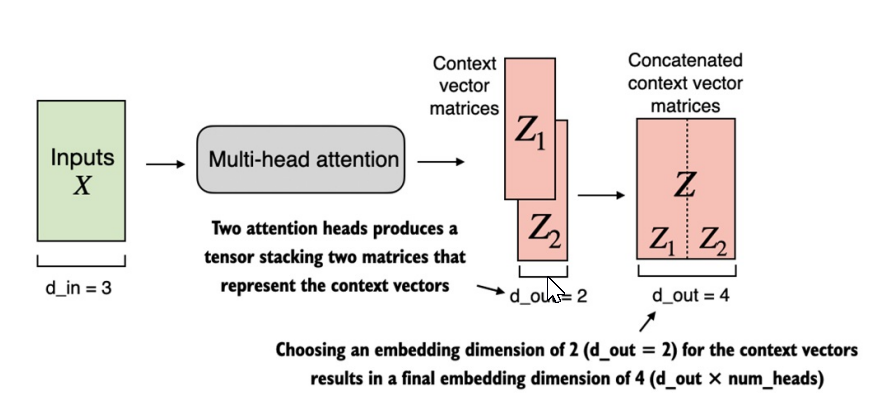
-
Trong
MultiHeadAttentionWrappertriển khai ở code trên, nếu có 2 attention heads và embedding_dim = 2, thì đầu ra sẽ là 1 context vector có dim_out = 2 x 2 = 4.
Chia nhỏ weights
-
Thay vì duy trì 2 lớp CausalAttention riêng biệt như phần trước, ta có thể kết hợp chúng lại vào lớp
MultiHeadAttention. -
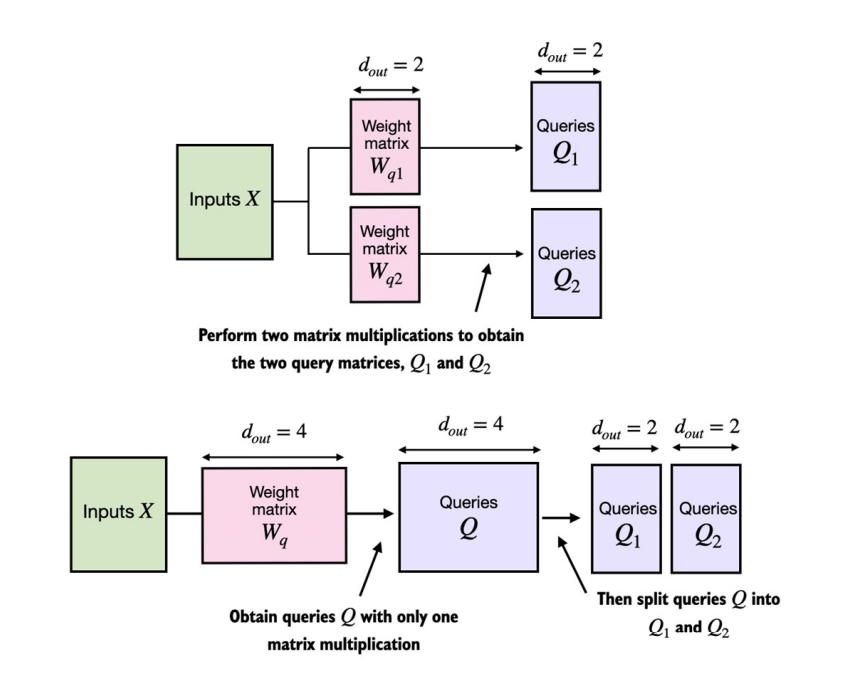
-
Như implement class trước thì ta thiết lập cơ chế multi-head bằng cách gộp lại các lớp CausalAttention. Còn ở phần chia nhỏ weights này ta sẽ xử lí với các tensor có số chiều lớn hơn, sau đó chia nhỏ cho từng head để trích xuất các đặc trưng riêng biệt.
-
Theo dõi code triển khai tại
10. Multi-head-attention.ipynb.