3. Coding Attention Mechanisms (Part 03)
3.4. Cơ chế self-attention đơn giản có trainable weights
-
Điểm khác biệt quan trọng nhất ở phần này so với phần trước là việc
các trainable weights matricessẽ được cập nhật trong quá trình huấn luyện. -
Ta sẽ triển khai qua 2 bước:
-
Bước 1: Viết code chi tiết từng bước (giống phần no weights)
-
Bước 2: Gom thành 1 class Python để import vào LLM architecture (sẽ triển khai ở các phần sau)
-
Từng bước tính trainable weights
-
Theo dõi code minh họa tại
7. Self-attention-trainable.ipynb. -
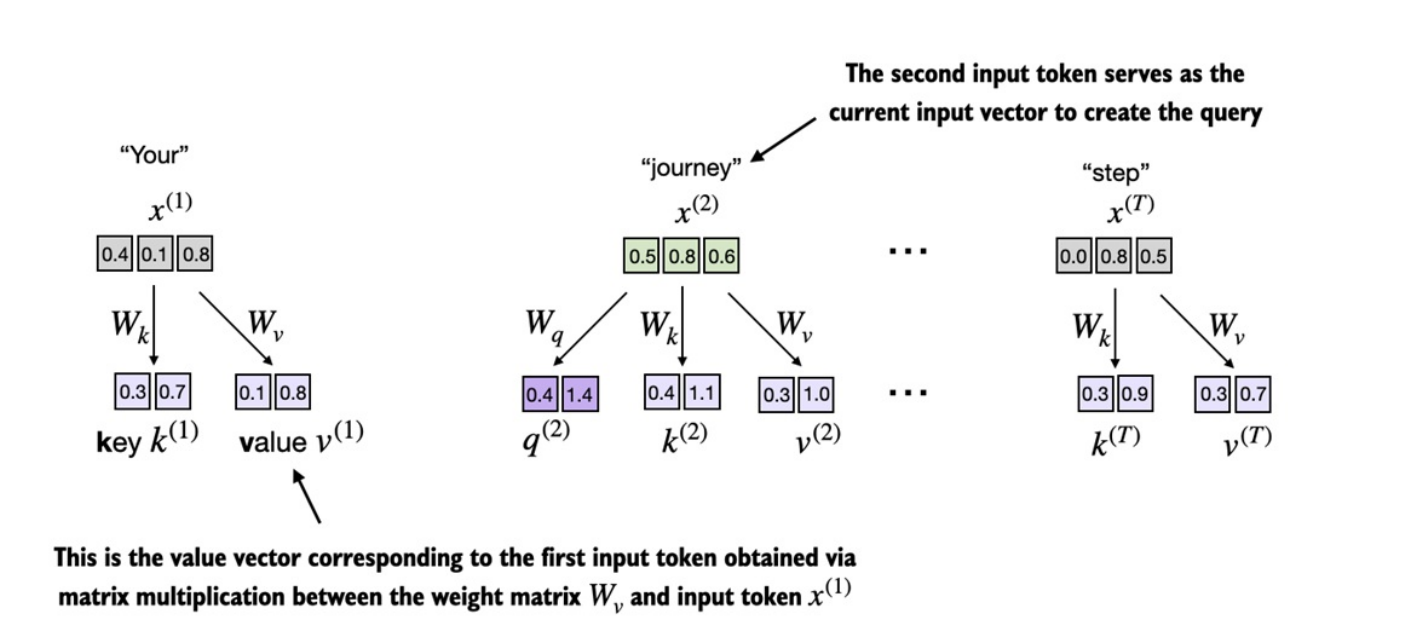
Trước tiên ở phần này sẽ có thêm
3 weights matricescó thể huấn luyện được: -
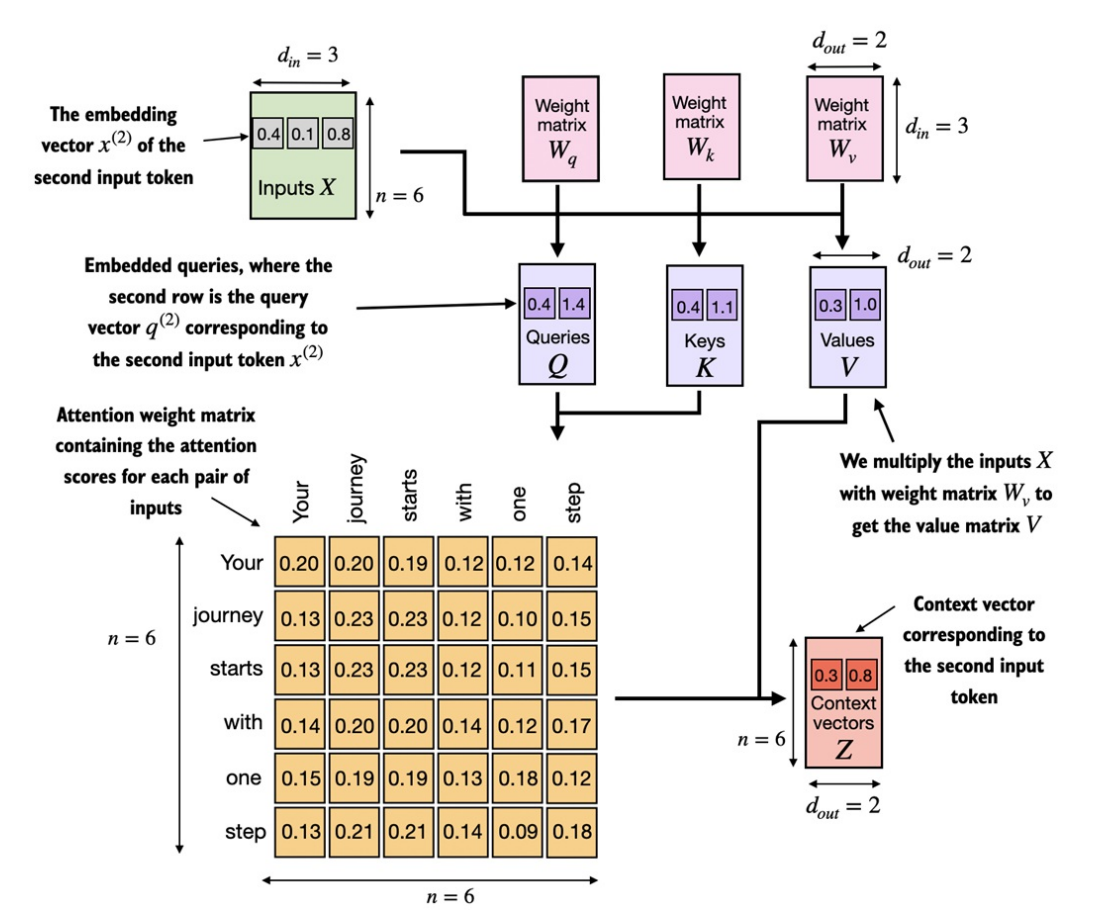
Ba ma trận này dùng để
chiếucáctoken đầu vàođã đượcembeddingsang 3 loại vector khác nhau:query (q),key (k),value (v). -
-
Ở ảnh trên,
input token thứ 2được chọn làmquery input. -
Vector query được tính bằng nhân ma trận giữa và weights matrix :
-
Tương tự với key và value :
-
-
Lý do tách ra 3 loại vector:
-
Query (q): vector dùng để đi xét với các vector khác.
-
Key (k): vector dùng để xét khi các vector khác tìm tới mình.
-
Value (v): vector chứa các đặc trưng về ngữ nghĩa.
-
-
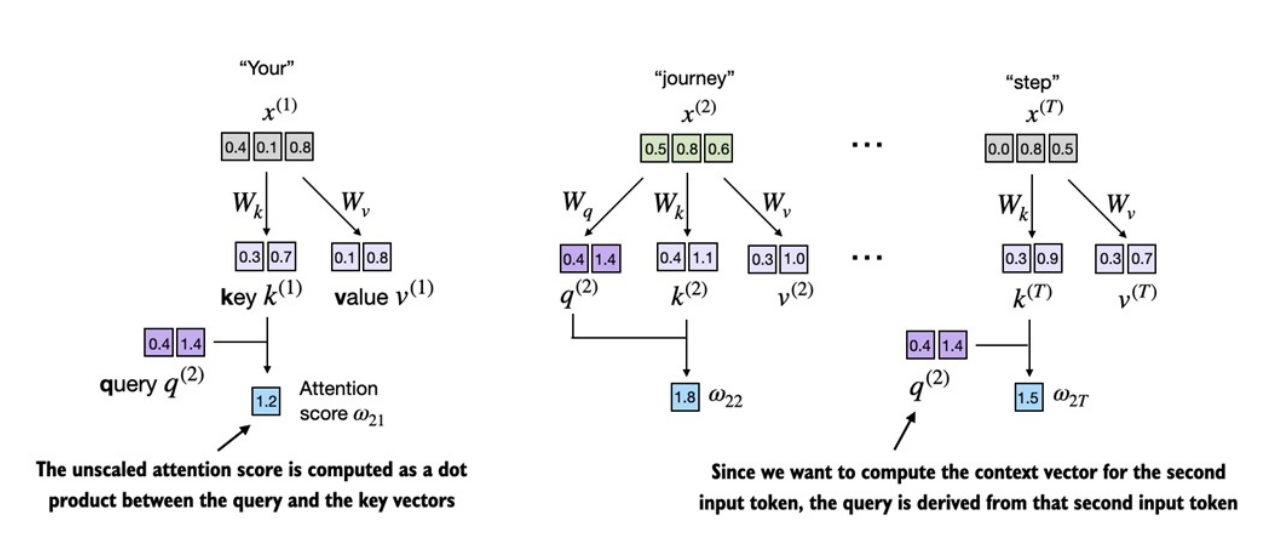
- Vì đang tính
context vectorchotoken 2nênattention scoresđược tính bằng với các .
- Vì đang tính
-
attention scoresđược tính bằngdot producttương tự cơ chếself-attention đơn giảnở phần trước. Điểm khác là ở đây được tính giữa vectorqueryvà vectorkey, vớiquerylà vector biểu diễntokenđang xét vàkeylà các vector biểu diễn cáctokensẽ được "so sánh" với query. -
-
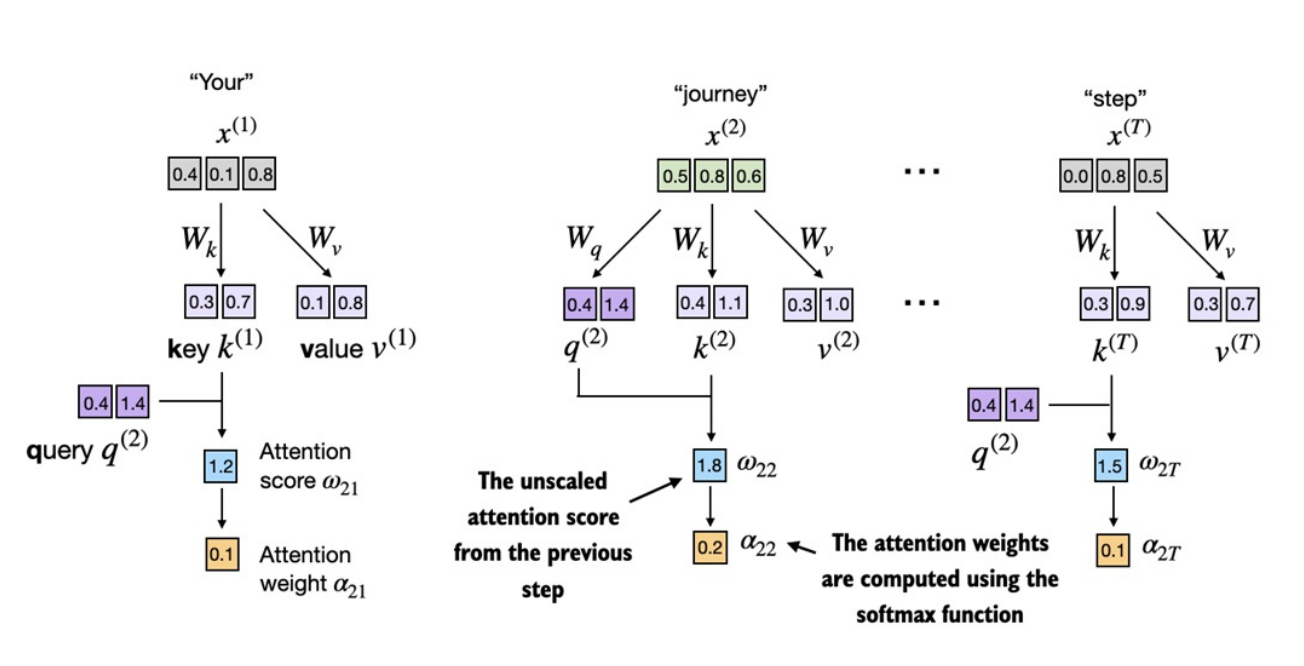
Ta sẽ tiến hành tính toán
attention weightsbằng cách điều chỉnhattention scoresvới hàmsoftmaxđã thực nghiệm ở phần trước. -
Điểm khác so với phần trước là ta sẽ chuẩn hóa
attention scoresbằng cáchchia cho căn bậc hai của embedding dimensioncủakeys:- với là embedding dimension keys.
-
Lý do cho việc
scaled dot-product attentionnày làcải thiện quá trình trainingbằng cáchtránh gradient nhỏ. Ví dụ:-
Giả sử dot-product là [28, 23, 21, 12, 6, 19] và embedding dim = 1024
-
Không scale: softmax gần như [≈ 1, 0, 0, 0, 0, 0].
-
Scale với : softmax thành [0.2211, 0.1891, 0.1776, 0.1341, 0.1112, 0.1669]. Gradient lan truyền tốt hơn.
-
-
-
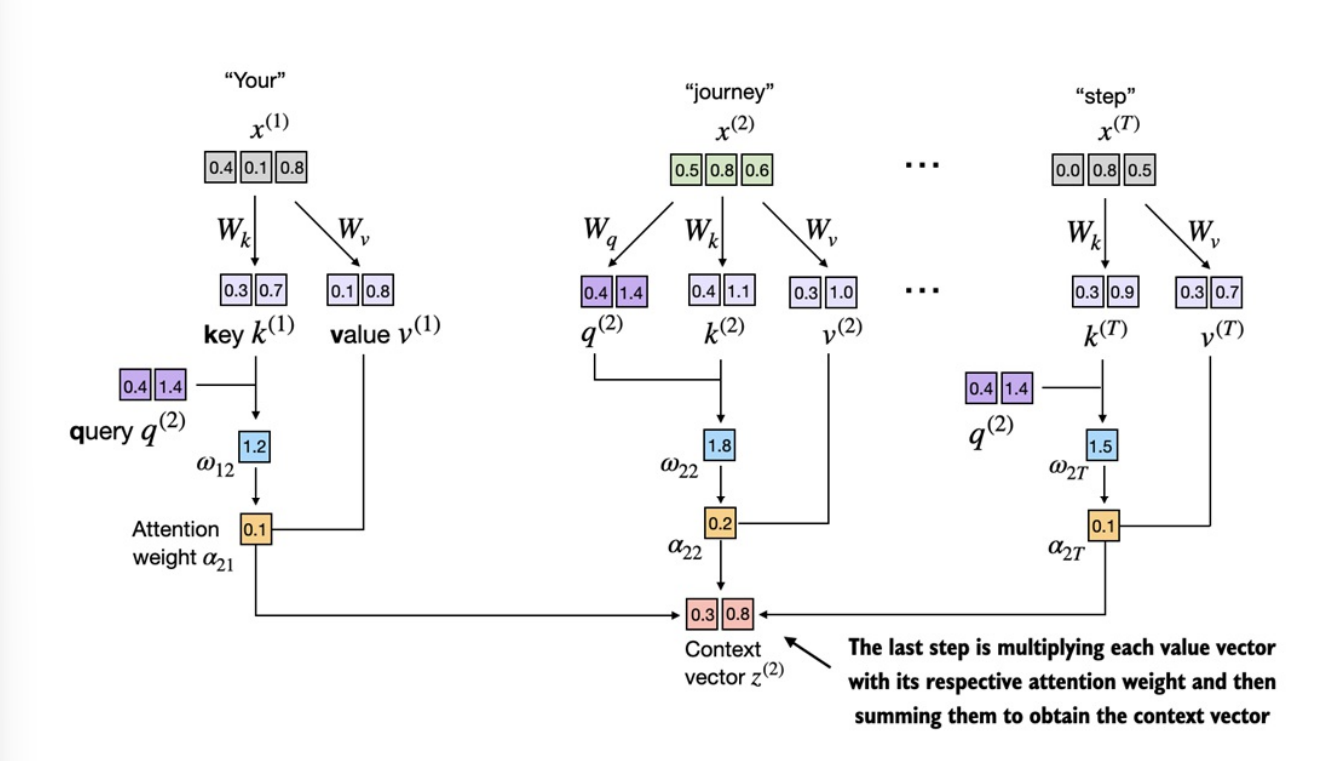
Bước cuối cùng là tính
context vectornhư hình ở trên. Tương tự như ở phần trước nhưng thay vì được tạo bằng tổng cácinput vectornhân vớiattention weighttương ứng thì ở đây sẽ là tổng cácvalue (v) vectornhân vớiattention weighttương ứng:
Tại sao lại là query, key & value?
-
3 khái niệm này được mượn từ information retrieval & databases, nơi dữ liệu được lưu trữ, tìm kiếm & truy xuất.
-
Query (q): dùng để biểu diễn phần tử hiện tại mà mô hình đang muốn hiểu rõ hơn, dùng để so sánh với các phần tử khác xem cần chú ý đến phần tử nào.
-
Key (k): dùng để so khớp (match) với query, mỗi phần tử đầu vào đều có 1 key tương ứng.
-
Value (v): Tương tự như key-value trong databases. Sau khi mô hình xác định được các key nào liên quan tới query, nó sẽ lấy ra các value tương ứng.
Triển khai Python class cho self-attention
-
Theo dõi code minh họa tại
8. Self-attention-class.ipynb. -
-
Trong
self-attention, ta biến đổiinput vectorthông qua 3 ma trận trọng số: , , . -
Sau đó, tính
attention scoresdựa trên các vector & vector thu được. -
attention scoresđược chuẩn hóa qua hàmsoftmaxđể trả vềattention weights. -
Nhân
attention weightsvới các vector tương ứng để ra được cáccontext vector.
-
-
Ta có thể cải thiện version
SelfAttention_v1bằng cách sử dụng các tầngnn.Linearcủa Pytorch. Bản chất của lớp Linear này là thực hiện phép tính . Nếu ta tắt bias (tức là ), thì nó chính xác là . -
nn.Linearkhởi tạo weights tiên tiến hơn (ví dụ Xavier initialization hoặc Kaiming initialization), giúp mô hình học ổn định và tránh gradient quá lớn/nhỏ. -
Ngoài ra,
nn.Linearcó cơ chế tự khởi tạo trọng số được tối ưu sẵn, thay vì dùngtorch.rand(). -
Triển khai version
SelfAttention_v2tại8. Self-attention-class.ipynb.