3. Coding Attention Mechanisms (Part 04)
3.5. Che đi (mask) các từ phía sau với cơ chế causal attention
-
Ở phần này, ta sẽ biến đổi cơ chế
self-attentiontiêu chuẩn để tạo ra cơ chếcausal attention- một thành phần cốt lõi của Transformer. -
Causal attention, còn gọi là masked attention, là một dạng chuyên biệt của self-attention. Cơ chế này giới hạn mô hình chỉ được "nhìn thấy" các token đầu vào trước đó và hiện tại khi xử lí bất kì token nào. Điều này trái ngược với cơ chế self-attention tiêu chuẩn, vốn cho phép "nhìn thấy" toàn bộ chuỗi các token đầu vào.
-
Do đó, khi tính toán
attention scores, causal attention đảm bảo mô hình chỉ tính đến các token xuất hiệntại hoặc trướctoken hiện tại trong chuỗi. -
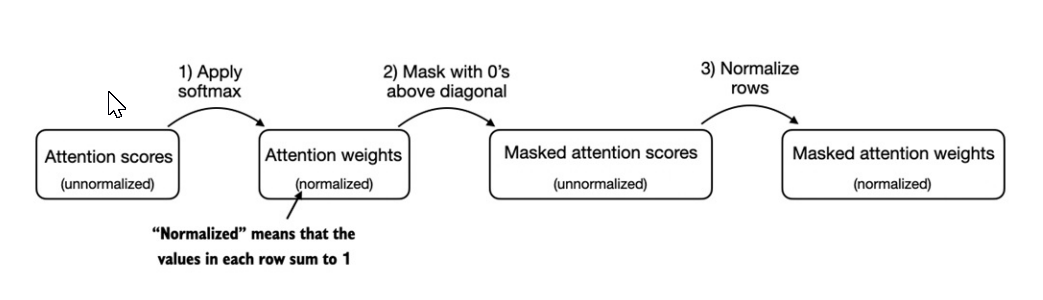
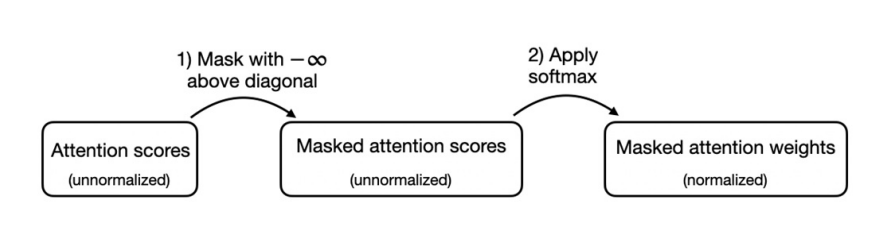
Ở hình phía dưới, cơ chế
causal attentionche (mask) các attention weights ở phía trên đường chéo chính. Điều này đảm bảo với 1 đầu vào đã cho, LLM không thể lấy các token tương lai khi tính toán cáccontext vectors. -

-
Theo dõi code minh họa tại - Theo dõi code minh họa tại
9. Causal-attention.ipynb.-
Version 01:
-
-
Version 02:
-
-
Mask thêm các attention weights với dropout
-
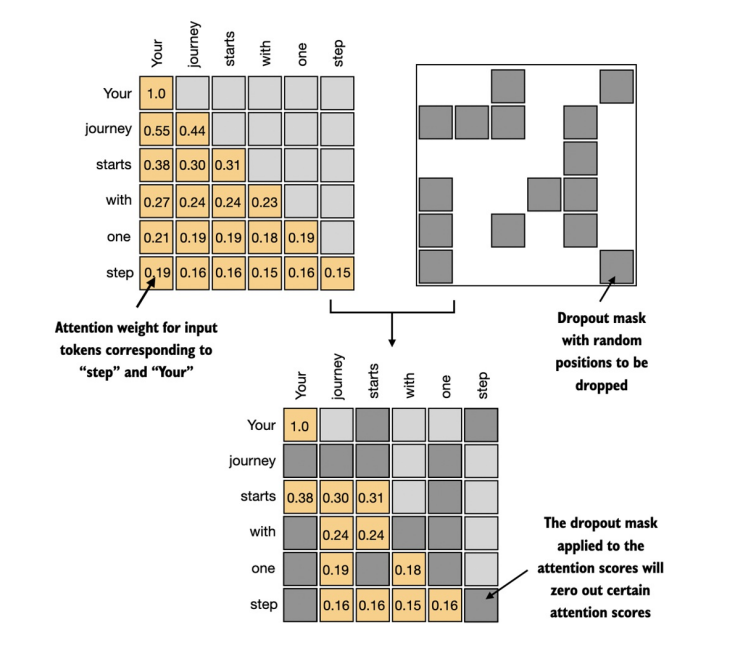
Nếu
casual masklà để ngăn mô hình ăn gian trong quá trình học khi "nhìn" các future token, thìdropoutlà để tránh mô hình overfitting vào một tập đơn vị nào đó trong hidden layer. Lưu ý rằng dropout chỉ được sử dụng trong quá trình training. -
Mục tiêu:
Chống overfitting -
-
Được minh họa ở hình trên, sau khi sử dụng
causal mask, ta thêm 1dropout maskđể gán giá trị 0 một cách ngẫu nhiên nhằm giảm overfitting trong quá trình training. -
-
Ở phần này ta đã tìm hiểu về cơ chế hoạt động và triển khai code của
causal attention. Ở phần sau ta sẽ mở rộng thêm và triển khai cơ chếmulti-head attentionđể triển khai cơ chế causal attention song song.