1. Thống kê mô tả
Trung bình cộng (Mean)
-
Kí hiệu:
-
Ý nghĩa: Điểm cân bằng của tập dữ liệu.
-
Công thức:
-
Cộng tất cả lại rồi chia cho số phần tử .
Khoảng cách (Residuals)
-
Kí hiệu:
-
Ý nghĩa: Cho biết mỗi điểm dữ liệu cách xa mức trung bình bao nhiêu.
-
Công thức:
-
Lấy từng con số trong tập dữ liệu trừ đi số trung bình cộng (
mean) đã tính.
Bình phương (Square)
-
Kí hiệu:
-
Ý nghĩa: Triệt tiêu dấu âm, ngoài ra Các giá trị càng xa trung bình khi bình phương lên sẽ càng lớn, giúp mô hình "nhạy cảm" hơn với các giá trị bất thường.
-
Công thức:
-
Bình phương tất cả các
khoảng cáchvừa tìm được. Việc này giúp biến các số âm thành số dương để chúng không triệt tiêu nhau khi cộng lại.
Phương sai (Variance)
-
Kí hiệu:
-
Ý nghĩa: Đo lường mức độ phân tán của dữ liệu. Phương sai cao nghĩa là các giá trị nằm rải rác xa nhau; phương sai thấp nghĩa là chúng tập trung sát giá trị trung bình.
-
Công thức:
-
Cộng tất cả các giá trị
bình phươnglại rồi chia cho . Đây là giá trị trung bình của các bình phương khoảng cách.
Độ lệch chuẩn (Standard Deviation)
-
Kí hiệu:
-
Công thức:
-
Lấy căn bậc hai của
phương sai. Vì đã bình phương, nên bước này giúp đưa giá trị về đúng đơn vị đo ban đầu của dữ liệu.
2. Phân phối (Distribution)
- Trong xác suất thống kê, Phân phối là cách mà các giá trị của dữ liệu được trải ra hoặc tập trung lại.
Phân phối Bernoulli (Bernoulli Distribution)
-
Đây là phân phối đơn giản nhất, giống như "nguyên tử" của xác suất. Nó chỉ dành cho những sự kiện có đúng 2 kết quả: Đúng/Sai, Thắng/Thua, 0/1.
-
Đặc điểm: Chỉ có 1 lần thử duy nhất.
-
Tham số: (xác suất thành công).
-
Xác suất thất bại sẽ là .
-
Ví dụ: Tung đồng xu 1 lần (Ngửa là 1, Sấp là 0).
-
Ứng dụng trong ML: Đây là nền tảng của các bài toán
Phân loại nhị phân (Binary Classification). Khi bạn dự đoán một email là Spam hay không, mô hình đang tính xác suất theo phân phối Bernoulli.
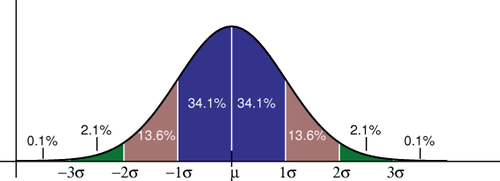
Phân phối chuẩn (Gaussian/Normal Distribution)
-
Đặc điểm: Dữ liệu tập trung nhiều nhất ở giữa (Mean) và thưa dần về hai phía.
-
Tham số:
- (mean): Quyết định vị trí đỉnh chuông.
- (độ lệch chuẩn): Quyết định độ rộng/dẹp của chuông.
-
Quy luật 68-95-99.7:
- 68% dữ liệu nằm trong khoảng .
- 95% dữ liệu nằm trong khoảng .
- 99.7% dữ liệu nằm trong khoảng .
-
Ứng dụng trong ML:
-
Nhiều thuật toán như Linear Regression giả định rằng sai số của dữ liệu tuân theo phân phối chuẩn.
-
Dùng để phát hiện Outliers: Nếu một điểm dữ liệu nằm ngoài khoảng (vùng 0.3% hiếm hoi), nó thường bị coi là dữ liệu rác hoặc bất thường.
-
-
Phân phối Nhị thức (Binomial Distribution)
-
Nếu Bernoulli là tung đồng xu 1 lần, thì Phân phối Nhị thức là tung đồng xu đó lần và đếm xem có bao nhiêu lần ra mặt Ngửa.
-
Đặc điểm: Gồm nhiều lần thử Bernoulli độc lập với nhau.
-
Tham số:
- : Số lần thử.
- : Xác suất thành công của mỗi lần.
-
Công thức: Xác suất để có đúng lần thành công trong lần thử:
-
-
: Số cách sắp xếp (tổ hợp).
-
— Xác suất của các lần Thành công.
-
— Xác suất của các lần Thất bại
-